Table of Contents
List of Tables
Table of Contents
Thank you for purchasing BinDiff, the leading executable-comparison tool for reverse engineers that need to analyze patches, malware variants, or are generally interested in the differences between two executables. This manual is intended to help you to get up to speed quickly.
In order to make best use of BinDiff, it is very helpful to spend a bit of time familiarizing yourself with the concepts and algorithms behind BinDiff. For this, we recommend reading Chapter 3, Understanding BinDiff, which explains the behind-the-scenes, Chapter 4, Core Functionality, which explains the basic elements of the user interface. Ideally, we would like you to also read Chapter 6, A basic walk-through Analyzing a Microsoft Patch (a walkthrough through analyzing a simple security update) and Chapter 7, Advanced Usage (a walk-through through porting your symbols and comments from one disassembly to the next). Don't worry - after Chapter 3, Understanding BinDiff, there's not a lot of text to parse and mostly screenshots to look at.
We hope that you have a great experience using our product!
The following typographical conventions are used in this document:
- Italic
- Used for new terms, URLs, email addresses as well as the name of commands and utilities.
Constant width- Indicates elements of code, configuration options, variables and their values, functions, modules the contents of files, or the output from commands.
- Constant width bold
- Shows commands or other text that should be typed literally by the user. Also used for emphasis in command output.
Constant width italic- Shows text that should be replaced with user-supplied values.
- BinDiff is now open source: https://github.com/google/bindiff
- IDA: Support IDA Pro 8.3, minimum required version is 8.0
- IDA: Replace obsolete input type `A` in "Import symbols and Comments" dialog
- IDA: More robust handling of functions without names
- Windows: Delay-load `dbghlp.dll` so that WinDbg debugging works as expected
- Command line differ: Add option to just produce similarity scores, but no actual `.BinDiff` files
- Internal changes to remove C++ exceptions in code
- Fix a memory leak using the SQLite database class
- Use faster Abseil maps in differ engine
- Increased cut-off values for discarding large functions in BinExport
- IDA: Support IDA Pro 7.6 SP1, minimum required version is still 7.4
- Ghidra: The BinExport Ghidra extension is now included in the package. This is still considered beta and will require to manually export files from Ghidra in order to bindiff them.
- Binary Ninja: A BinExport plugin for Binary Ninja is included. This is still considered beta. Use the third-party BD Viewer or export manually to bindiff files.
- Function names are now exported in `.BinDiff` result files, making post-processing easier
- Improved speed in native BinExport plugins. Exporting from IDA Pro and Binary Ninja is up to 30% faster compared to BinDiff 6.
- User interface: Shipping with updated Java runtime based on JDK 16 on all platforms, including Linux
- User interface: Better HiDPI support on all platforms
- Installation packages: disassembler plugins are now symlinked into per-user plugin directories instead of being copied into the target disassembler installation.
- User configuration now uses JSON format, making future changes easier and fixes some long-standing serialization issues.
- macOS: Notarized binaries/package compatible with macOS 11 "Big Sur"
- macOS: Universal Binaries supporting ARM64 (aka "Apple Silicon") and x86-64
- Fixed a security issue where a specially crafted .BinExport file could lead to an out-of-bounds memory access. Thanks to Mickey Jin of Trend Micro Mobile Security Research Team for the report.
- Built on IDA SDK 7.4
- Experimental support for the Ghidra disassembler (see the BinExport documentation)
- Bug fixes to the core BinDiff engine
- Improved porting of symbols and comments
- Merged config file for command-line, plugin and UI
- Better macOS integration
- Fixed a security issue with the Windows Installer (b/140218119). Thanks to Eran Shimony of CyberArk Labs for the report.
- Ported BinDiff and BinExport plugins to IDA 7
- Built on IDA SDK 7.2
- Improvements and bug fixes to the core BinDiff engine
- Fixed symbol and comment porting
- Config file locations and default install paths changed
- On Windows and macOS, ship with a bundled Java runtime based on OpenJDK 11
- Built on IDA SDK 6.95
- Improvements to the core BinDiff engine
- Using the open source version of BinExport that writes the new BinExport2 format, based on Protocol Buffers. Source is available here.
- macOS support
- New human-readable config file format for the UI
- UI change: Switched to left-click drag for the graph views
- Built on IDA SDK 6.8, so this is the new minimum version required
- Support for AArch64 (a.k.a. ARM64)
- Increase maximum export file size to 2GiB
- Improvements to the core BinDiff engine
- New import symbols and comments feature to mark imported comments as coming from an external library
- No OS X support for this version
- Support for IDA 6.5 or higher
- Support for Windows 8 and 8.1
- Support for large operand sizes used by the AVX/AVX2 instructions
- Improvements to the core BinDiff engine
- No OS X support for this version
- The user interface for visual diff has been rewritten
- Call graph views
- Proximity browsing in flowgraphs and callgraphs
- New "combined" view of flowgraphs
- Faster graph rendering and better rendering quality
- Improved instruction match representation
- Improved search functionality
- IDA comments are exported
- Selection history with undo and redo
- Copyable basic block and function node contents
- Multi-tab layout
- Organize multiple diffs in workspaces
- New exporter format based on Google Protocol Buffers
- Incremental diffing - manually confirm matches that will be kept in another diff iteration while reassiging others, allows to iteratively improve the result
- Auto-generated comments no longer get ported
- New column in Matched functions table allows to keep track of one's progress for comment porting
- Support for the Dalvik architecture (used by Android)
- Mac OS X support
- Support for IDA Pro 6.0 or higher (version 3.2.2 adds support for IDA Pro 6.2)
- Big change: New internal diff engine that produces more detailed and more accurate results
- Fixed an edge-layout bug that led to improperly connected basic blocks
- Improved HTML report generation
- Removed configuration dialog from IDA plugin. The plugin configuration can be changed via its XML-based configuration file
- Added menu items to IDA to allow for a global hotkey and fast access to subviews
- New statistics subview
- Linux version of the BinDiff Plugin for IDA (to be downloaded separately)
- Windows only: Removed dependency on Windows registry, configuration data is now stored in plain XML files
- Compatibility with Windows Vista: BinDiff Plugin for IDA no longer writes to the IDA directory anymore
- Updated Documentation in XHTML format
- Improved installation experience using Windows Installer
- Bugfix: Labelled addresses are now properly displayed
We have added two significant new features to zynamics BinDiff:
- HTML output generation. zynamics BinDiff 1.8 can now generate an HTML file summarizing the changes detected and providing detailed information on changes to the call graph and ambiguous situations.
- Edge-Vector matching. zynamics BinDiff 1.8 features a new algorithm for generating initial fixedpoints, leading to a significant reduction in diffing time on larger disassemblies (several thousand functions) where no symbols are available.
Many changes have occured between versions 1.5 and 1.6, some very visible, others revolving around the core functionality.
-
New methods to generate initial fixedpoints:
- String matching
- Creates fixedpoints from functions that reference identical strings
- Recursive function matching
- Creates fixedpoints from functions that call themselves
- Prime Products
- Fixedpoints are created for functions that contain the same instructions in identical quantities (but not necessarily in the same order)
- Initial fixedpoints by name now ignores “unknown_libnames” and similar categories of functions
- New isomorphism algorithm for function-level diffing
- New visualization option for visual diff color corresponding nodes in identical colors
- New CPU-independent instruction-level isomorphism algorithm
- New comment porting algorithm based on the above;
currently ports:
- Local labels
- Anterior/posterior comments
- Regular and repeatable comments
- Regular and repeatable function comments
- Operand to standard enum member
- Added processor: SPARC
-
New fully CPU-independent mode for not explicitly supported processors (used by default if the CPU is not supported). This means that all CPUs that IDA supports are supported using this default mode. However, CPUs with conditional execution (IA64, ARM) may yield suboptimal results.
Please contact
<zynamics-support@google.com>to let us know of any processors that you would like to have explicit support for, as using explicitly supported CPUs result in higher-quality matches. - Added temp directory for sane storage of all temporary graphs.
- Option to color functions identified as changed within the database. Functions colored with this option will be colored in any graphs created by the user through IDA's graphing facilities.
Table of Contents
Since BinDiff is an add-on product to IDA, it requires a working installation of Hex-Rays IDA Pro version 7.4 of above Please note that support for legacy versions of IDA Pro has been discontinued.
Alternatively, BinDiff ships with beta quality plugins/extensions for both Binary Ninja and Ghidra.
To install BinDiff to your workstation, perform the following steps:
- Download the Windows installation package from the
releases page:
Download
bindiff8.msi. - Double-click the downloaded installation package to start the Setup Wizard. Note that the user installing the package will need administrative privileges to perform the installation.
-
On the initial Welcome page, click . You are asked to read and confirm the Apache 2.0 License.
To accept the License Agreement, check I accept the terms in the License Agreement and click .
-
On the Custom Setup page, you can select the features you want to install. By default, all product features will be installed. You can remove a feature by clicking the icon next to it and select .
To change the location where BinDiff gets installed, select BinDiff and click the button. The Change destination folder dialog appears, allowing you to enter a custom installation path. Click to confirm your choice and close the dialog.
Once you are done customizing Setup, click .
- You are asked to provide the full path to your installation of Hex-Rays IDA Pro. If Setup was able to detect an installation of IDA, its directory is already set as a default. To manually browse for the IDA directory, click .
- Click and then to begin the installation which usually takes only a moment.
- To close the Setup Wizard, click .
By default, customers of BinDiff receive Debian GNU/Linux installation packages. The following Linux distributions are supported:
- Debian 12 (“Bookworm”)
- Debian testing (“Trixie”)
- Ubuntu 22.04 (“Jammy Jellyfish”)
To request an installation package/installation instructions for a distribution other than Debian or Ubuntu, please file a bug in the BinDiff Issue Tracker. The remainder of this section assumes that the distribution you are installing BinDiff on Debian GNU/Linux or Ubuntu.
To install BinDiff to your workstation, perform the following steps:
- Download the Debian package from the
releases page:
Download
bindiff_8_amd64.deb. -
The package is GPG signed with Google's "Linux Packages Signing Authority" key.
Verify as follows:
gpg --recv-key 7721F63BD38B4796 gpg --verify bindiff_8_amd64.deb.asc
- Open a shell with administrative privileges. On Debian, use the su command, on Ubuntu use the command sudo -i. Then change the current working directory to the location where you downloaded the Debian package to.
- Type dpkg -i bindiff_8_amd64.deb to begin the installation.
To install BinDiff to your Mac, perform the following steps:
-
Download the macOS disk image from the releases page: Download
BinDiff8.dmg.The disk image and all binaries are code-signed and notarized, so macOS should be able to install without further messages/warnings.
- Double-click the downloaded installation package to verify and mount the image. Then double-click Install BinDiff to start the Installer. Note that the user installing the package will need administrative privileges to perform the installation.
-
On the initial Welcome page, click . You are asked to read and confirm the Apache 2.0 License.
To accept the License Agreement, check Agree and click .
- Click and then to begin the installation which usually takes only a moment.
- To close the Installer, click .
Table of Contents
This section provides background information about the inner workings of BinDiff. It is recommended reading for anyone who wants to get the most out of the product, and for anyone who wants to understand the details of the different configuration options.
BinDiff works on the abstract structure of an executable, ignoring the concrete assembly-level instructions in the disassembly. Every function gets a signature, based on the structure of the (normalized) flow graph of the function. The signature consists of:
- Number of codeblocks
- Number of edges between codeblocks
- Number of calls to subfunctions
Once the two sets of signatures (for the two executables) have been generated, initial matches are created. This works by selecting a subset of all functions in each executable which share a common characteristic. A match is created if a signature occurs once (and only once) in both examined subsets of signatures.
After this step, callgraphs (graphs which contain information about the calls-to relations between functions) are used to generate more matches: If a match is known, the subsets of all functions called from a matched function are examined. These subsets are significantly smaller than the set of all functions, thus the propability for finding new unique matches is a lot higher. This process is repeated until no new matches can be found.
This means that after you have successfully run BinDiff, you have a list of functions that were successfully associated with each other, as well as two lists of functions that could not be associated.
BinDiff has a list of function attributes (see below) suitable for generating matches. It starts on a global level, considering all functions of the binary and calculates the first attribute for every function. There are several possible outcomes:
- An attribute is unique in both binaries. The function is matched.
- An attribute appears several times in both binaries - the matching is ambiguous. BinDiff proceeds with a "drill down" step, only considering the equivalent sets of functions for that attribute. Drilling down means trying the next best attribute until we either run out of algorithms, match functions uniquely or the set dissolves because an attribute does not match any of its functions.
- An attribute does not have a match in the other binary. The function is kept in the unmatched set.
After the initial global matching step the parents (callers) and children (callees) of each new match are considered. BinDiff tries to match functions in the set of parents and children by performing a "drill down" step as described above on each. Finally BinDiff performs basic block matching for all newly matched functions and matches functions called from matched basic blocks (function: call reference matching). This concludes global matching for a single attribute. The whole process is restarted on the remaining unmatched functions using the next best attribute.
Function attributes are used in one of two ways. Either canonically per function or per edge. Edge matching tries to match edges (which represent calls in the call graph or jumps in the flow graphs) if source and target function attributes match. Thus edge matching is the stronger criterium, yielding better matches in general. However, since it is possible to have a lot of edges per vertex in a graph (this is especially true for callgraphs, where the number of edges often grows super linearily in the number of vertices) edge matching may potentially be very slow. If you do encounter performance problems for certain binaries you should first try to disable edge matching based algorithms. Also, do not hesitate to send the offending binaries to the zynamics team at Google - we are always trying to improve performance bottlenecks and are grateful for samples.
Function matching algorithms ordered roughly by resulting match quality:
- function: hash matching
-
Matches functions based on a hash of the original raw function bytes. Thus two functions matched by this algorithm should be identical on the byte level.
match quality: very good
algorithm performance: very good
- function: name hash matching
-
Matches functions based on a hash of their names. Only real names are considered, names which have been auto-generated by the disassembler are not used. This is one of the few algorithms that can match imported functions, i.e. functions that do not have an actual body in the binary. False matches are highly unlikely.
match quality: very good
algorithm performance: very good
- function: edges flowgraph MD index
-
Matches callgraph edges based on their source and target function's MD indices. Thus calls between two structurally identical functions are matched.
match quality: very good
algorithm performance: medium
- function: edges callgraph MD index
-
Matches callgraph edges based on their callgraph MD index. This means the callgraph leading to that particular call is structurally identical in both binaries. Match quality depends on how deep the callstack leading up to this edge is: the deeper the less likely is a false match.
match quality: good
algorithm performance: medium
- function: MD index matching (flowgraph MD index, top down), function: MD index matching (flowgraph MD index, bottom up)
-
Matches functions based on their structure using the MD index. Since the MD index takes a topological graph ordering as one of it's inputs we can parametrize it by whether we sort the graph vertices into levels following calls from the entrypoint (top down) or callers from the exit points (bottom up).
match quality: good
algorithm performance: very good
- function: prime signature matching
-
Matches functions based on their instruction prime products. Each mnemonic gets assigned a unique small prime number. These primes are multiplied for all instructions of the function. This yields a structurally invariant, instruction order independent, product to be subsequently used as a matching attribute.
match quality: good
algorithm performance: very good
- function: MD index matching (callGraph MD index, top down), function: MD index matching (callGraph MD index, bottom up)
-
Matches functions based on their position in the callgraph. The call graph leading up to that function must be structurally identical as viewed from the program entrypoint (top down) or its exits (bottom up).
match quality: good
algorithm performance: very good
- function: edges proximity MD index
-
Matches functions based on their local call graph neighborhoods. Calls and callees are only followed two levels deep as seen from the function in question.
match quality: medium
algorithm performance: poor
- function: relaxed MD index matching
-
Matches functions based on their relaxed MD indices. The MD index is calculated without taking topological order into account. This means only the in-edges and out-edges in the function's local neighborhood are considered.
match quality: medium
algorithm performance: medium
- function: address sequence
-
Matches functions in order based on their entry point addresses. This is a special matching step that is especially useful during drill downs. Since it would indiscriminately match all functions if not further constrained there are two additional requirements: first the functions in question must already be equivalent according to the relaxed MD index and the flow graph MD index. Second, the two sets of equivalent functions in both binaries must be of equal size.
match quality: poor
algorithm performance: very good
- function: string references
-
Matches functions based on their referenced string data. All strings referenced from the functions in question are put into a combined hash which is subsequently used as the matching attribute if at least one string is referenced. This is a good algorithm for matching error handling code which often has very little structure (and thus won't get matched by the stronger algorithms) but lots of references to error message strings.
match quality: medium
algorithm performance: very good
- function: loop count matching
-
Matches functions based on the number of loops. Only applied if at least one loop is present.
match quality: poor
algorithm performance: very good
- function: call sequence matching(exact), function: call sequence matching(topology), function: call sequence matching(sequence)
-
Special algorithm that is only used for functions with matched parents (callers). The point of the call at the call site is determined as a tuple: topological basic block level, instruction number in the basic block, address. The child function (callee) is matched if basic block level and instruction number match (exact), if only the basic block level match (topology) or simply ordered by call site address (sequence). This produces very weak matches in general, but may be a good strategy if the parent function was matched correctly. In that case it is not unlikely that it will call functions in the same order in both binaries.
match quality: very poor
algorithm performance: good
Basic block matching on flow graph level is algorithmically very similar to function matching. Global attribute matching is followed by drill downs and by trying to match in the reduced set of parents/children of matched basic blocks.
Basic block matching algorithms ordered roughly by resulting match quality:
- basicBlock: edges prime product
-
Flowgraph edges are matched if source and target basic block instruction prime products match. Thus both basic blocks contain identical instructions, potentially ordered differently.
match quality: very good
- basicBlock: hash matching (4 instructions minimum)
-
Basic blocks are matched based on a binary hash of their raw bytes. Only used on basic blocks with at least 4 instructions.
match quality: very good
- basicBlock: prime matching (4 instructions minimum)
-
Basic blocks are matched based on their instruction prime product. Only used on basic blocks with at least 4 instructions.
match quality: very good
- basicBlock: call reference matching
-
Basic blocks are matched if they call at least one function and all called functions have been matched.
match quality: very good
- basicBlock: string reference matching
-
Basic blocks are matched if they reference at least one string and that string is the same in both binaries.
match quality: very good
- basicBlock: edges MD index (top down), basicBlock: MD index matching (top down), basicBlock: edges MD index (bottom up), basicBlock: MD index matching (bottom up), basicBlock: relaxed MD index matching
-
Basic blocks are matched based on their position in the flowgraph.
match quality: good
- basicBlock: prime matching (0 instructions minimum)
-
Works like the previous prime matching step but with the minimum number of instructions constraint lifted.
match quality: medium
- basicBlock: edges Lengauer Tarjan dominated
-
Matches the back edges of loops which have been determined using the Lengauer-Tarjan algorithm.
match quality: medium
- basicBlock: loop entry matching
-
Matches basic blocks that are loop anchors, i.e. targets of a back edge.
match quality: low
- basicBlock: self loop matching
-
Matches basic blocks that have self loops.
match quality: low
- basicBlock: entry point matching, basicBlock: exit point matching
-
Matches the entry/exit point basic blocks. The entry point is uniquely identified by the function and usually has an indegree of 0. Exit points are vertices with outdegree 0.
match quality: low
- basicBlock: instruction count matching, basicBlock: jump sequence matching
-
Special matching steps that are only applied to basic blocks that are structurally equivalent based on their MD indices. Basic blocks are matched according to their number of instructions or simply ordered by address.
match quality: very low
- basicBlock: propagation (size==1)
-
Special matching step of last resort. Single unmatched parents/children of matched basic blocks are matched - with no regard of their content.
match quality: very low
The confidence value displayed by BinDiff is the average algorithm confidence (match quality) used to find a particular match weighted by a sigmoid squashing function. The values aren't simply averaged because few single weak matches in an otherwise perfectly matched function/binary shouldn't drag the confidence down too much. Analogously, even a few strong matches will not "rescue" a binary pair matched primarily by address sequence and similarily weak algorithms.
The similarity value for a function is a weighted sum taking the following factors into account:
-
Weight ~25%: quota of matched flow graph edges to total edges
-
Weight ~15%: quota of matched basic blocks to total basic blocks
-
Weight ~10%: quota of matched instructions to total instructions
-
Weight ~50%: difference in flow graph MD index
The similarity value for the whole binary is a weighted sum taking the following factors into account:
-
Weight ~35%: quota of matched flow graph edges to total edges
-
Weight ~25%: quota of matched basic blocks to total basic blocks
-
Weight ~10%: quota of matched functions to total functions
-
Weight ~10%: quota of matched instructions to total instructions
-
Weight ~20%: difference in call graph MD index
For the more technically inclined and for users that are interested in in-depth information on BinDiff and IDA, the following documents are worth reading:
“Graph-Based Comparison of Executable Objects”. http://www.zynamics.com/downloads/bindiffsstic05-1.pdf . SSTIC ’05, Symposium sur la Sécurité des Technologies de l’Information et des Communications. . 2005.
“Structural Comparison of Executable Objects”. http://www.zynamics.com/downloads/dimva_paper2.pdf . 161-173. Detection of Intrusions and Malware & Vulnerability Assessment. . 2004. 3-88579-375-X.
Table of Contents
To begin using BinDiff, start IDA, load a database and press Ctrl+6 to display the plugin main window.
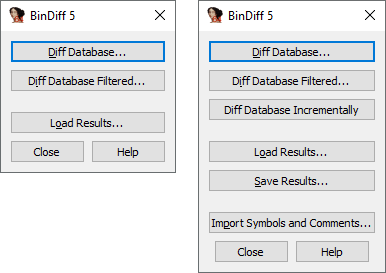
-
Browse for an IDA database and start the diffing process. Can also be accessed by pressing Shift+D or using the , menu option.
-
Like , but allows to select an address range to diff.
-
Browse for a diffing result to load. This functionality is also available via the , , menu option.
-
Saves the result of the current diffing session to be loaded later using . This can also be accessed using the , , menu option.
-
Allows to transfer function names and/or individual comments from the other database.
To view functions, that were not matched during the diff, use the Primary Unmatched and the Secondary Unmatched subviews. The first one displays functions that are contained in the currently open database and were not associated to any function of the diffed database, while the Secondary Unmatched subview contains functions that are in the diffed database but were not associated to any functions in the first.
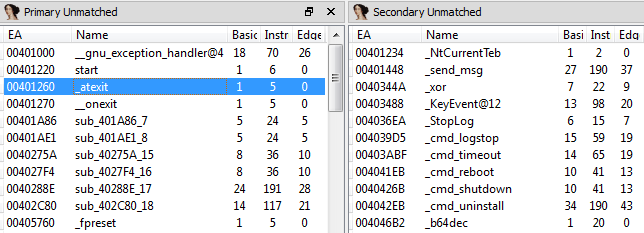
The meaning of the columns is as follows:
- EA
-
The effective address of the function that is not associated with any other function.
- Name
-
The name of the function that is not associated with any other function.
- Basic Blocks, Instructions, Edges
-
The number of code blocks, instructions and edges in the flow graph in this function. These can be used to identify similar functions manually.
The Matched Functions subview displays the results of the diffing e.g. pairs of functions that are associated with each other.
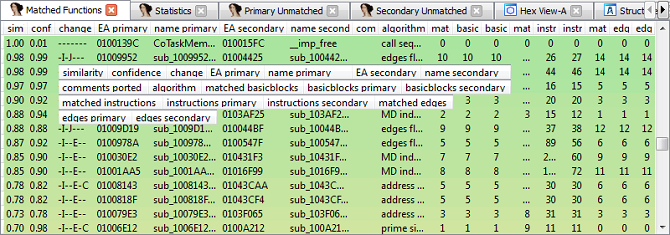
The columns have the following meaning:
- similarity
-
A value between zero and one indicating how similar two matched functions are. A value of exactly one means the two functions are identical (in regard to their instructions, not their memory addresses). Values less than one mean the function has changed parts. Please note that BinDiff only considers basic blocks, edges and mnemonics for calculating similarity values. In particular, instructions may differ in their operands, immediate values and addresses and will still be considered equal if the mnemonics match.
- confidence
-
A value between zero and one indicating the confidence of the similarity score. Note that this value represents the calculated confidence score for the matching algorithms that are enabled in the configuration file. It is possible to get a high similarity match with a small confidence score or vice versa. This simply means that a weak algorithm has found a good match or a good algorithm has found a weak match.
- change
-
This column characterizes the difference between the two matched functions. There can be any combination of the following change types, indicated by single letters:
- Graph (G): there have been structural changes in the function. Either the number of basic blocks or the number of edges differs or unmatched edges exist.
- Instruction (I): either the number of instructions differs or at least one mnemonic has changed.
- Operand (O): not yet implemented
- Jump (J): indicates a branch inversion.
- Entrypoint (E): the entry point basic blocks have not been matched or are different.
- Loop (L): the number of loops has changed.
- Call (C): at least one of the call targets hasn't been matched.
- EA primary, name primary
-
The effective address (EA) and the name of the function in the currently open IDA database.
- EA secondary, name secondary
-
The effective address (EA) and the name of the function in the foreign (secondary) database.
- algorithm
-
The algorithm that led to the match. For a list of algorithms in this version of BinDiff, refer to Chapter 3, Understanding BinDiff and Chapter 5, Configuration .
- matched basic blocks, basic blocks primary, basic blocks secondary
-
Number of total matched basic blocks per function, total number of basic blocks in the first (primary) function and total number of basic blocks in the second function.
- matched instructions, instructions primary, instructions secondary
-
Like the above, but totalling instructions instead of basic blocks.
- matched edges, edges primary, edges secondary
-
These three value describe the total of the matched control flow graph edges, as well as the number of the edges in the control flow graph of the primary and secondary functions.
Right-clicking on one of the matched functions brings up a context menu:
-
Transfer individual comments from the other database for the selected function.
-
Displays a graphical representation of the differences between the selected function in the two databases using the BinDiff Graphing GUI.
-
Copies the contents of the Matched Functions subview to the system clipboard. The copied text is tabular data separated by spaces.
BinDiff displays functions from IDA as highlighted flowgraphs with colors indicating special properties of edges and code blocks.
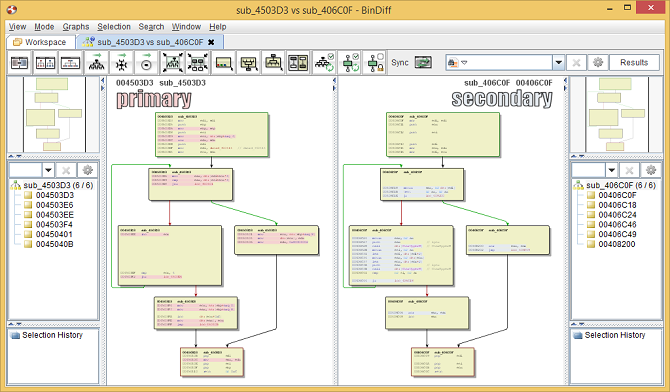
Green arrows represent conditional branches that need to satisfy a certain condition to be taken, whereas red arrows represent conditional branches if the branch condition is not met as well as unconditional branches.
BinDiff relies on several heuristics to do its work. The behavior of the program is configurable to suit your needs. This section discusses the proper configuration of BinDiff.
If you are in a hurry to get started, just leave the configuration as is, the default settings of BinDiff are pre-configured for the most common use cases.
If you encounter performance problems with BinDiff, would like to adapt the confidence values based on your experience or want to test algorithms individually you may modify the config file directly. Note that BinDiff needs to be restarted for changes to take effect (restart IDA).
Table 5.1. Location of BinDiff configuration files
| Platform | Location |
|---|---|
| Windows | %APPDATA%\BinDiff\bindiff.xml |
| Linux | ~/.bindiff/bindiff.xml |
| macOS | ~/Library/Application Support/BinDiff/bindiff.xml |
The following configuration options are available:
ui-
java-binary-
Path to the Java application launcher binary. If empty or unset, BinDiff will try to auto-detect a suitable Java VM.
Default value (Windows):
(BinDiff installation directory)\jre\bin\javaw.exeDefault value (macOS, Linux): (empty)
java-vm-options-
Additional arguments to pass to the Java application launcher. There should usually be no need to set this.
Default value: (unset)
max-heap-size-mb-
Maximum amount of Java heap space for the UI. If unset, defaults to 75% of physical system memory (minimum 512MiB). There should usually be no need to set this.
Default value: (unset)
directory-
Path to the BinDiff installation directory.
Default value: (BinDiff installation directory)
server-
IP address to use for internal IPC.
Default value:
127.0.0.1 port-
IP port to use for internal IPC.
Default value:
2000 retries-
Reserved, do not use.
Default value:
20
ida-
directory-
Path to the IDA Pro installation directory.
Default value: (IDA Pro installation directory)
executable-
Name of the IDA Pro executable for analyzing 32-bit binaries. If unset, BinDiff uses
ida.exe(Windows) orida(macOS, Linux).Default value: (unset)
executable64-
Name of the IDA Pro executable for analyzing 64-bit binaries. If unset, BinDiff uses
ida64.exe(Windows) orida64(macOS, Linux).Default value: (unset)
threads-
How many threads to use when batch-diffing. If set to
max-hw, BinDiff will use as many threads as there are logical processors in the system.Default value:
2 function-matching,basic-block-matching-
Specifies the order of the internal matching algorithms and the associated confidence values. For a list of supported algorithms, please refer to Chapter 3, Understanding BinDiff .
For each
stepelement, the following attributes are supported:confidence- A value between zero and one indicating the confidence when using the specified algorithm.
algorithm- Name of the matching algorithm. Note that the name is case-sensitive.
In the following section, we will perform a short walk-through explaining the use of BinDiff to reverse-engineer a security patch. Our example will be MS08-063.
From MS08-063:
A remote code execution vulnerability exists in the way that Microsoft Server Message Block (SMB) Protocol handles specially crafted file names. An attempt to exploit the vulnerability would require authentication because the vulnerable function is only reachable when the share type is a disk, and by default, all disk shares require authentication. An attacker who successfully exploited this vulnerability could install programs; view, change, or delete data; or create new accounts with full user rights.
Microsoft also states that the exploitability is “inconsistent exploit likely” , indicating that some complications are to be expected for someone writing an exploit.
Begin by disassembling srv.sys in the unpatched version. Then follow up by disassembling the patched variant of the file. Make sure the IDB of the unpatched version is not opened in another instance of IDA. Then press Ctrl+6 and select the unpatched version as the target for the comparison using the button.
After a few moments, BinDiff should display the Matched Functions subview. To display the functions that changed, click the similarity column to sort by function similarity. Functions that were changed in the patch will have a similarity score of less than one.

In the image above, a total of three functions were changed:
-
SrvRestartRawReceive(x) -
SrvIssueQueryDirectoryRequest(x, x, x, x, x, x, x, x) -
SrvFsdRestartPrepareRawMdlWrite(x)
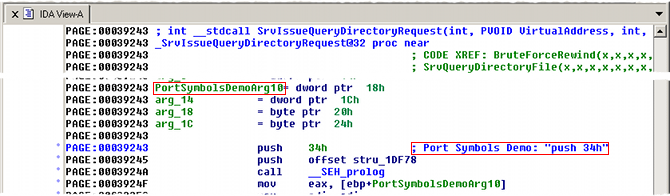
Let's examine the change in the middle: SrvIssueQueryDirectoryRequest . If
you press Ctrl+E with the cursor positioned
on this function, the BinDiff graph GUI is launched.
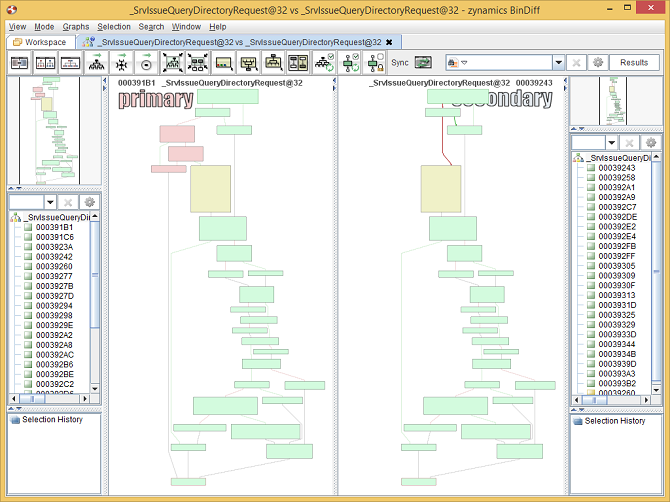
The BinDiff Graph GUI displaying the flow graph of
SrvIssueQueryDirectoryRequest
.
The nodes in green indicate basic blocks that have identical instruction mnemonics in both executables (although operands to individual assembly instructions might have changed), whereas the red nodes indicate basic blocks to which our comparison algorithms were unable to find equivalents. A third category, yellow nodes, indicates nodes for which the algorithms could find equivalents, but which had some instructions changed between versions.
Let's zoom in on the two smaller blocks on the left hand side that have been inserted right before the large red block.
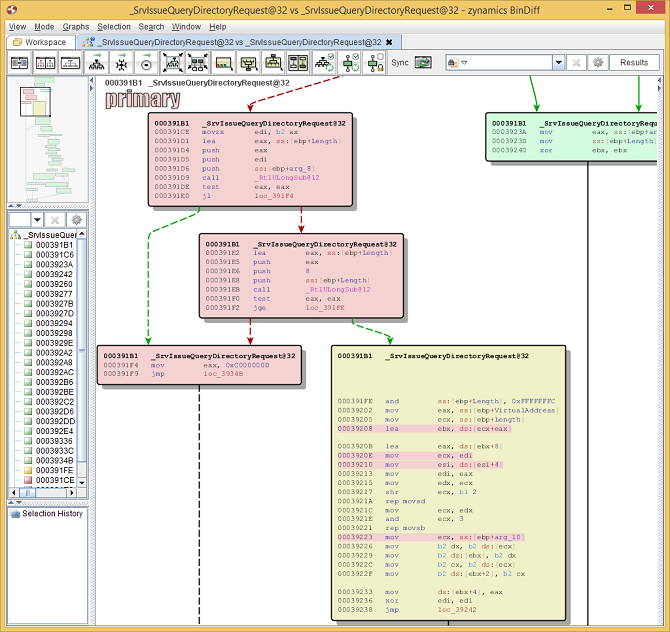
Zoomed-in on the changed parts of the function.
We can see that a 16-bit value is loaded into EDI, and
some calls to RtlUlongSub
have been introduced which were not present in the old
version. If you click the Lock
View icon on the toolbar, and thus allow the two
halves of the graph to be desynchronized, you can start
right-click-panning on the right hand side to see the big
yellow block as it was in the unpatched version.
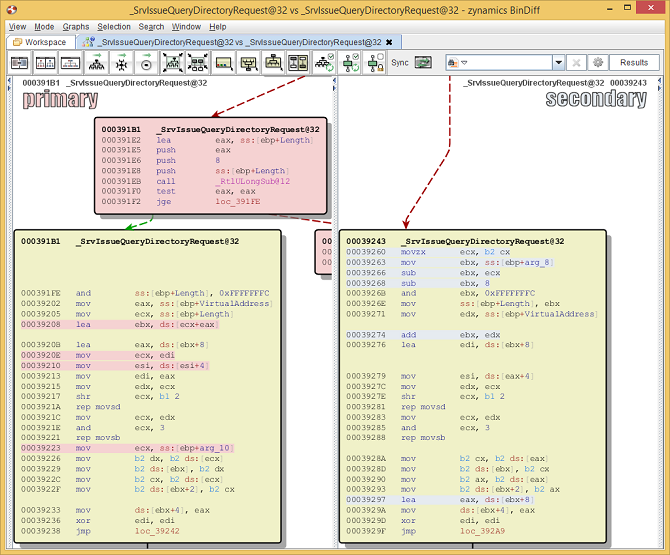
Estimating the set of additional changes.
Now, what did
change? The old version takes a 16-bit value, subtracts it
from arg_8, subtracts 8
from arg_8, and then
rounds the result down to the next value divisible by 4.
The result of this calculation is then added to the local
variable VirtualAddress,
and the number of bytes specified by this 16-bit value are
copied to the buffer pointed to by the result.
The new version replaces the regular integer arithmetic
with calls to RtlUlongSub, which enforces that no
integer underflow occurs e.g. the result of a subtraction is
always smaller than the value that was subtracted from. In
pseudo-code:
index = (arg_8 - shortval - 8) & 0xFFFFFFFC; memcpy(&destination[index + 8], eax->member_4, shortval);
So the risk here was for an attacker to be able to choose
arg_8 and shortval in such a manner that
index + 8 remains
negative allowing for memory corruption right before
destination. The patched
version eliminates this problem by ensuring that the
arithmetic never drops below zero.
Table of Contents
From time to time, we will publish documents on advanced usage of our products on our website http://www.zynamics.com/. Please check the publications section frequently to see any additional information that becomes available.
Aside from analyzing security problems, symbol porting is one of the most useful features of BinDiff. Given an IDB in which comments and names have been added, you can use BinDiff to pull these names and comments into a new IDB for a related executable.
In order to do this, please perform the following steps:
- Open the IDB into which you wish to port the comments.
- Press Ctrl+6 and compare the IDB to the IDB from which you wish to import the comments.
- After diffing is complete, switch to the regular IDA disassembly and hit Ctrl+6 again.
- Click the button.
All comments, local variable names and global variable names that BinDiff can associate between the two executables will be ported.
Warning
The names of local variables etc. in the current IDB will be overwritten!
- A.1. General Questions
- A.2. Installation
A.1. General Questions |
|
|
A.1.1. |
How come the Matched functions subview is empty? |
|
Please refer to Chapter 5, Configuration on how to properly configure BinDiff and follow the instructions contained within. If the problem persists although you have enabled several algorithms for creating initial fixedpoints, please contact us. |
|
|
A.1.2. |
Where did the Changed functions subview go? |
|
The functionality of both the Changed functions and the Matched functions subviews was merged. Changed functions are functions with a similarity of less than one, whereas identical functions have a similarity score of exactly one. For a more detailed description, refer to the section called “The Matched Functions Subview”. |
|
A.2. Installation |
|
|
A.2.1. |
Administrative installation of BinDiff |
|
For simple administrative installs just prepend msiexec /quiet (no output at all) or msiexec /passive (progress bar only) to the installation package: msiexec /passive bindiff6.msi. The installation package can also be deployed via Group Policies just like any other Windows Installer package. |
|
Report BinDiff bugs using the issue tracker at
https://bugs.zynamics.com/bindiff (requires a free Google
account).